🐳 Docker, Deploying LiteLLM Proxy
You can find the Dockerfile to build litellm proxy here
Quick Start
To start using Litellm, run the following commands in a shell:
# Get the code
git clone https://github.com/BerriAI/litellm
# Go to folder
cd litellm
# Add the master key
echo 'LITELLM_MASTER_KEY="sk-1234"' > .env
source .env
# Start
docker-compose up
- Basic
- With CLI Args
- use litellm as a base image
- Kubernetes
- Helm Chart
Step 1. CREATE config.yaml
Example litellm_config.yaml
model_list:
- model_name: azure-gpt-3.5
litellm_params:
model: azure/<your-azure-model-deployment>
api_base: os.environ/AZURE_API_BASE # runs os.getenv("AZURE_API_BASE")
api_key: os.environ/AZURE_API_KEY # runs os.getenv("AZURE_API_KEY")
api_version: "2023-07-01-preview"
Step 2. RUN Docker Image
docker run \
-v $(pwd)/litellm_config.yaml:/app/config.yaml \
-e AZURE_API_KEY=d6*********** \
-e AZURE_API_BASE=https://openai-***********/ \
-p 4000:4000 \
ghcr.io/berriai/litellm:main-latest \
--config /app/config.yaml --detailed_debug
Get Latest Image 👉 here
Step 3. TEST Request
Pass model=azure-gpt-3.5 this was set on step 1
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "azure-gpt-3.5",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Run with LiteLLM CLI args
See all supported CLI args here:
Here's how you can run the docker image and pass your config to litellm
docker run ghcr.io/berriai/litellm:main-latest --config your_config.yaml
Here's how you can run the docker image and start litellm on port 8002 with num_workers=8
docker run ghcr.io/berriai/litellm:main-latest --port 8002 --num_workers 8
# Use the provided base image
FROM ghcr.io/berriai/litellm:main-latest
# Set the working directory to /app
WORKDIR /app
# Copy the configuration file into the container at /app
COPY config.yaml .
# Make sure your entrypoint.sh is executable
RUN chmod +x entrypoint.sh
# Expose the necessary port
EXPOSE 4000/tcp
# Override the CMD instruction with your desired command and arguments
# WARNING: FOR PROD DO NOT USE `--detailed_debug` it slows down response times, instead use the following CMD
# CMD ["--port", "4000", "--config", "config.yaml"]
CMD ["--port", "4000", "--config", "config.yaml", "--detailed_debug"]
Deploying a config file based litellm instance just requires a simple deployment that loads the config.yaml file via a config map. Also it would be a good practice to use the env var declaration for api keys, and attach the env vars with the api key values as an opaque secret.
apiVersion: v1
kind: ConfigMap
metadata:
name: litellm-config-file
data:
config.yaml: |
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-ca
api_base: https://my-endpoint-canada-berri992.openai.azure.com/
api_key: os.environ/CA_AZURE_OPENAI_API_KEY
---
apiVersion: v1
kind: Secret
type: Opaque
metadata:
name: litellm-secrets
data:
CA_AZURE_OPENAI_API_KEY: bWVvd19pbV9hX2NhdA== # your api key in base64
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: litellm-deployment
labels:
app: litellm
spec:
selector:
matchLabels:
app: litellm
template:
metadata:
labels:
app: litellm
spec:
containers:
- name: litellm
image: ghcr.io/berriai/litellm:main-latest # it is recommended to fix a version generally
ports:
- containerPort: 4000
volumeMounts:
- name: config-volume
mountPath: /app/proxy_server_config.yaml
subPath: config.yaml
envFrom:
- secretRef:
name: litellm-secrets
volumes:
- name: config-volume
configMap:
name: litellm-config-file
To avoid issues with predictability, difficulties in rollback, and inconsistent environments, use versioning or SHA digests (for example, litellm:main-v1.30.3 or litellm@sha256:12345abcdef...) instead of litellm:main-latest.
[BETA] Helm Chart is BETA. If you run into an issues/have feedback please let us know https://github.com/BerriAI/litellm/issues
Use this when you want to use litellm helm chart as a dependency for other charts. The litellm-helm OCI is hosted here https://github.com/BerriAI/litellm/pkgs/container/litellm-helm
Step 1. Pull the litellm helm chart
helm pull oci://ghcr.io/berriai/litellm-helm
# Pulled: ghcr.io/berriai/litellm-helm:0.1.2
# Digest: sha256:7d3ded1c99c1597f9ad4dc49d84327cf1db6e0faa0eeea0c614be5526ae94e2a
Step 2. Unzip litellm helm
Unzip the specific version that was pulled in Step 1
tar -zxvf litellm-helm-0.1.2.tgz
Step 3. Install litellm helm
helm install lite-helm ./litellm-helm
Step 4. Expose the service to localhost
kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT
Your OpenAI proxy server is now running on http://127.0.0.1:4000.
That's it ! That's the quick start to deploy litellm
Options to deploy LiteLLM
| Docs | When to Use |
|---|---|
| Quick Start | call 100+ LLMs + Load Balancing |
| Deploy with Database | + use Virtual Keys + Track Spend (Note: When deploying with a database providing a DATABASE_URL and LITELLM_MASTER_KEY are required in your env ) |
| LiteLLM container + Redis | + load balance across multiple litellm containers |
| LiteLLM Database container + PostgresDB + Redis | + use Virtual Keys + Track Spend + load balance across multiple litellm containers |
Deploy with Database
Docker, Kubernetes, Helm Chart
Requirements:
- Need a postgres database (e.g. Supabase, Neon, etc) Set
DATABASE_URL=postgresql://<user>:<password>@<host>:<port>/<dbname>in your env - Set a
LITELLM_MASTER_KEY, this is your Proxy Admin key - you can use this to create other keys (🚨 must start withsk-)
- Dockerfile
- Kubernetes
- Helm
- Helm OCI Registry (GHCR)
We maintain a separate Dockerfile for reducing build time when running LiteLLM proxy with a connected Postgres Database
docker pull ghcr.io/berriai/litellm-database:main-latest
docker run \
-v $(pwd)/litellm_config.yaml:/app/config.yaml \
-e LITELLM_MASTER_KEY=sk-1234 \
-e DATABASE_URL=postgresql://<user>:<password>@<host>:<port>/<dbname> \
-e AZURE_API_KEY=d6*********** \
-e AZURE_API_BASE=https://openai-***********/ \
-p 4000:4000 \
ghcr.io/berriai/litellm-database:main-latest \
--config /app/config.yaml --detailed_debug
Your OpenAI proxy server is now running on http://0.0.0.0:4000.
Step 1. Create deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: litellm-deployment
spec:
replicas: 3
selector:
matchLabels:
app: litellm
template:
metadata:
labels:
app: litellm
spec:
containers:
- name: litellm-container
image: ghcr.io/berriai/litellm:main-latest
imagePullPolicy: Always
env:
- name: AZURE_API_KEY
value: "d6******"
- name: AZURE_API_BASE
value: "https://ope******"
- name: LITELLM_MASTER_KEY
value: "sk-1234"
- name: DATABASE_URL
value: "po**********"
args:
- "--config"
- "/app/proxy_config.yaml" # Update the path to mount the config file
volumeMounts: # Define volume mount for proxy_config.yaml
- name: config-volume
mountPath: /app
readOnly: true
livenessProbe:
httpGet:
path: /health/liveliness
port: 4000
initialDelaySeconds: 120
periodSeconds: 15
successThreshold: 1
failureThreshold: 3
timeoutSeconds: 10
readinessProbe:
httpGet:
path: /health/readiness
port: 4000
initialDelaySeconds: 120
periodSeconds: 15
successThreshold: 1
failureThreshold: 3
timeoutSeconds: 10
volumes: # Define volume to mount proxy_config.yaml
- name: config-volume
configMap:
name: litellm-config
kubectl apply -f /path/to/deployment.yaml
Step 2. Create service.yaml
apiVersion: v1
kind: Service
metadata:
name: litellm-service
spec:
selector:
app: litellm
ports:
- protocol: TCP
port: 4000
targetPort: 4000
type: NodePort
kubectl apply -f /path/to/service.yaml
Step 3. Start server
kubectl port-forward service/litellm-service 4000:4000
Your OpenAI proxy server is now running on http://0.0.0.0:4000.
[BETA] Helm Chart is BETA. If you run into an issues/have feedback please let us know https://github.com/BerriAI/litellm/issues
Use this to deploy litellm using a helm chart. Link to the LiteLLM Helm Chart
Step 1. Clone the repository
git clone https://github.com/BerriAI/litellm.git
Step 2. Deploy with Helm
Run the following command in the root of your litellm repo. This will set the litellm proxy master key as sk-1234
helm install \
--set masterkey=sk-1234 \
mydeploy \
deploy/charts/litellm-helm
Step 3. Expose the service to localhost
kubectl \
port-forward \
service/mydeploy-litellm-helm \
4000:4000
Your OpenAI proxy server is now running on http://127.0.0.1:4000.
If you need to set your litellm proxy config.yaml, you can find this in values.yaml
[BETA] Helm Chart is BETA. If you run into an issues/have feedback please let us know https://github.com/BerriAI/litellm/issues
Use this when you want to use litellm helm chart as a dependency for other charts. The litellm-helm OCI is hosted here https://github.com/BerriAI/litellm/pkgs/container/litellm-helm
Step 1. Pull the litellm helm chart
helm pull oci://ghcr.io/berriai/litellm-helm
# Pulled: ghcr.io/berriai/litellm-helm:0.1.2
# Digest: sha256:7d3ded1c99c1597f9ad4dc49d84327cf1db6e0faa0eeea0c614be5526ae94e2a
Step 2. Unzip litellm helm
Unzip the specific version that was pulled in Step 1
tar -zxvf litellm-helm-0.1.2.tgz
Step 3. Install litellm helm
helm install lite-helm ./litellm-helm
Step 4. Expose the service to localhost
kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT
Your OpenAI proxy server is now running on http://127.0.0.1:4000.
LiteLLM container + Redis
Use Redis when you need litellm to load balance across multiple litellm containers
The only change required is setting Redis on your config.yaml
LiteLLM Proxy supports sharing rpm/tpm shared across multiple litellm instances, pass redis_host, redis_password and redis_port to enable this. (LiteLLM will use Redis to track rpm/tpm usage )
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/<your-deployment-name>
api_base: <your-azure-endpoint>
api_key: <your-azure-api-key>
rpm: 6 # Rate limit for this deployment: in requests per minute (rpm)
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-ca
api_base: https://my-endpoint-canada-berri992.openai.azure.com/
api_key: <your-azure-api-key>
rpm: 6
router_settings:
redis_host: <your redis host>
redis_password: <your redis password>
redis_port: 1992
Start docker container with config
docker run ghcr.io/berriai/litellm:main-latest --config your_config.yaml
LiteLLM Database container + PostgresDB + Redis
The only change required is setting Redis on your config.yaml
LiteLLM Proxy supports sharing rpm/tpm shared across multiple litellm instances, pass redis_host, redis_password and redis_port to enable this. (LiteLLM will use Redis to track rpm/tpm usage )
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/<your-deployment-name>
api_base: <your-azure-endpoint>
api_key: <your-azure-api-key>
rpm: 6 # Rate limit for this deployment: in requests per minute (rpm)
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-ca
api_base: https://my-endpoint-canada-berri992.openai.azure.com/
api_key: <your-azure-api-key>
rpm: 6
router_settings:
redis_host: <your redis host>
redis_password: <your redis password>
redis_port: 1992
Start litellm-databasedocker container with config
docker run --name litellm-proxy \
-e DATABASE_URL=postgresql://<user>:<password>@<host>:<port>/<dbname> \
-p 4000:4000 \
ghcr.io/berriai/litellm-database:main-latest --config your_config.yaml
Advanced Deployment Settings
1. Customization of the server root path (custom Proxy base url)
💥 Use this when you want to serve LiteLLM on a custom base url path like https://localhost:4000/api/v1
In a Kubernetes deployment, it's possible to utilize a shared DNS to host multiple applications by modifying the virtual service
Customize the root path to eliminate the need for employing multiple DNS configurations during deployment.
👉 Set SERVER_ROOT_PATH in your .env and this will be set as your server root path
export SERVER_ROOT_PATH="/api/v1"
Step 1. Run Proxy with SERVER_ROOT_PATH set in your env
docker run --name litellm-proxy \
-e DATABASE_URL=postgresql://<user>:<password>@<host>:<port>/<dbname> \
-e SERVER_ROOT_PATH="/api/v1" \
-p 4000:4000 \
ghcr.io/berriai/litellm-database:main-latest --config your_config.yaml
After running the proxy you can access it on http://0.0.0.0:4000/api/v1/ (since we set SERVER_ROOT_PATH="/api/v1")
Step 2. Verify Running on correct path
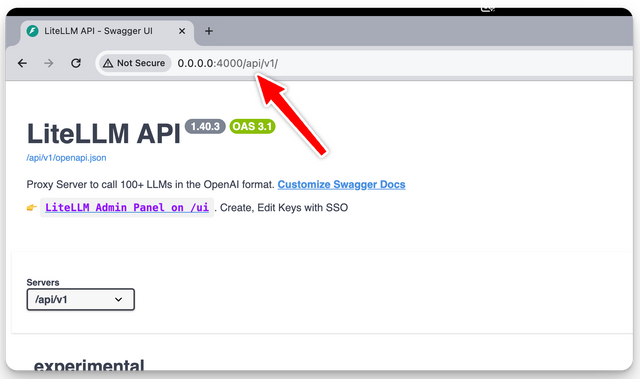
That's it, that's all you need to run the proxy on a custom root path
2. Setting SSL Certification
Use this, If you need to set ssl certificates for your on prem litellm proxy
Pass ssl_keyfile_path (Path to the SSL keyfile) and ssl_certfile_path (Path to the SSL certfile) when starting litellm proxy
docker run ghcr.io/berriai/litellm:main-latest \
--ssl_keyfile_path ssl_test/keyfile.key \
--ssl_certfile_path ssl_test/certfile.crt
Provide an ssl certificate when starting litellm proxy server
Platform-specific Guide
- AWS EKS - Kubernetes
- AWS Cloud Formation Stack
- Google Cloud Run
- Render deploy
- Railway
Kubernetes - Deploy on EKS
Step1. Create an EKS Cluster with the following spec
eksctl create cluster --name=litellm-cluster --region=us-west-2 --node-type=t2.small
Step 2. Mount litellm proxy config on kub cluster
This will mount your local file called proxy_config.yaml on kubernetes cluster
kubectl create configmap litellm-config --from-file=proxy_config.yaml
Step 3. Apply kub.yaml and service.yaml
Clone the following kub.yaml and service.yaml files and apply locally
Use this
kub.yamlfile - litellm kub.yamlUse this
service.yamlfile - litellm service.yaml
Apply kub.yaml
kubectl apply -f kub.yaml
Apply service.yaml - creates an AWS load balancer to expose the proxy
kubectl apply -f service.yaml
# service/litellm-service created
Step 4. Get Proxy Base URL
kubectl get services
# litellm-service LoadBalancer 10.100.6.31 a472dc7c273fd47fd******.us-west-2.elb.amazonaws.com 4000:30374/TCP 63m
Proxy Base URL = a472dc7c273fd47fd******.us-west-2.elb.amazonaws.com:4000
That's it, now you can start using LiteLLM Proxy
AWS Cloud Formation Stack
LiteLLM AWS Cloudformation Stack - Get the best LiteLLM AutoScaling Policy and Provision the DB for LiteLLM Proxy
This will provision:
- LiteLLMServer - EC2 Instance
- LiteLLMServerAutoScalingGroup
- LiteLLMServerScalingPolicy (autoscaling policy)
- LiteLLMDB - RDS::DBInstance
Using AWS Cloud Formation Stack
LiteLLM Cloudformation stack is located here - litellm.yaml
1. Create the CloudFormation Stack:
In the AWS Management Console, navigate to the CloudFormation service, and click on "Create Stack."
On the "Create Stack" page, select "Upload a template file" and choose the litellm.yaml file
Now monitor the stack was created successfully.
2. Get the Database URL:
Once the stack is created, get the DatabaseURL of the Database resource, copy this value
3. Connect to the EC2 Instance and deploy litellm on the EC2 container
From the EC2 console, connect to the instance created by the stack (e.g., using SSH).
Run the following command, replacing <database_url> with the value you copied in step 2
docker run --name litellm-proxy \
-e DATABASE_URL=<database_url> \
-p 4000:4000 \
ghcr.io/berriai/litellm-database:main-latest
4. Access the Application:
Once the container is running, you can access the application by going to http://<ec2-public-ip>:4000 in your browser.
Deploy on Google Cloud Run
Click the button to deploy to Google Cloud Run

Testing your deployed proxy
Assuming the required keys are set as Environment Variables
https://litellm-7yjrj3ha2q-uc.a.run.app is our example proxy, substitute it with your deployed cloud run app
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
Deploy on Render https://render.com/
Deploy on Railway https://railway.app
Step 1: Click the button to deploy to Railway

Step 2: Set PORT = 4000 on Railway Environment Variables
Extras
Run with docker compose
Step 1
- (Recommended) Use the example file
docker-compose.ymlgiven in the project root. e.g. https://github.com/BerriAI/litellm/blob/main/docker-compose.yml
Here's an example docker-compose.yml file
version: "3.9"
services:
litellm:
build:
context: .
args:
target: runtime
image: ghcr.io/berriai/litellm:main-latest
ports:
- "4000:4000" # Map the container port to the host, change the host port if necessary
volumes:
- ./litellm-config.yaml:/app/config.yaml # Mount the local configuration file
# You can change the port or number of workers as per your requirements or pass any new supported CLI augument. Make sure the port passed here matches with the container port defined above in `ports` value
command: [ "--config", "/app/config.yaml", "--port", "4000", "--num_workers", "8" ]
# ...rest of your docker-compose config if any
Step 2
Create a litellm-config.yaml file with your LiteLLM config relative to your docker-compose.yml file.
Check the config doc here
Step 3
Run the command docker-compose up or docker compose up as per your docker installation.
Use
-dflag to run the container in detached mode (background) e.g.docker compose up -d
Your LiteLLM container should be running now on the defined port e.g. 4000.